Shared Environment Configuration
Different situations may demand varying approaches to setting up environments to be used by developers during project
modification and enhancement. Broadleaf Commerce has always offered first-class support for the following development
scenario:
- Developers run code locally in an IDE against a local database
- The local database is a lightweight version of the real environment (enough data to facilitate development)
- Developers make any code and database schema changes required to facilitate a feature. Since the database is isolated local, he/she can wipe the database at any time and not worry about negative interaction with other devs.
- Schema changes will generally be represented in Liquibase or Flyway change logs that area managed in source control and facilitate schema modification and data migration when deploying dev changes to a more permanent environment.
There are numerous benefits with this approach, as there are much fewer occurrences of data problems resulting from developers
working and experimenting in a shared environment. This approach also facilitates offline development, as a dev is not
necessarily required to connect to a remote environment to get work done. This approach definitely remains our primary
recommendation for development teams using Broadleaf.
However, some circumstances demand that a common database be shared among developers during feature development and
maintenance. One of the most common reasons for this requirement is that the catalog size is to unwieldy and it doesn't
make sense for individual developers to run a database of that size locally, nor is it possible to run a reduced-dataset
version locally. Or, the schema employs advanced features of a commercial RDBMS and licensing considerations preclude
running local developer instances of the commercial database. Whatever the reason may be, some projects demand a shared
environment against which devs create and test code.
A shared environment traditionally has problems when using commercial Broadleaf Commerce - specifically the Enterprise and
Jobs/Events modules. The issue arises from the fact that a Broadleaf cluster is maintained in a Master/Slave configuration.
Important duties regarding messaging and scheduled job maintenace are enacted by nodes in the "master" status. However,
there is nothing differentiating a developer workstation node from a real, permanent integrated-dev environment node. As
a result, a developer can launch his/her codebase against the shared environment and end up as the master node. This can
be problemattic for a number of reasons:
- The developer is likely to run his/her code in debug mode. During that time, the master node duties are not being performed adequately. This can result in strange behavior on other nodes in the cluster where state is not cleaned up in a timely fashion or jobs are not performed when expected, leading to confusion around the overall functionality of the system.
- During debugging, the developer is also likely to establish some data-tier row-level locks as a result of performing normal operations. However, as debugging can be slow, the transaction surrounding those locks can be left open for a long time and can slow down performance of other nodes, or result in database deadlocks.
- If using the async features of the Jobs/Events module, a developer would generally want to consume any events emitted in a code flow on that same workstation, in order to review the entire flow of execution. However, that event is available to the cluster and there is no guarantee that the current developer workstation will consume the event. This can create exotic problems where one node issues an admin deployment, for example, and a developer workstation consumes the deployment request. Then, for whatever reason, the node is exited by the developer (he/she has no expectation of performing work for the cluster), and the deployment can be perceived to be in a weird state.
A workaround that has been used in the past is to create a separate, lightweight database for the jobs/events persistence
unit alone. This solves a lot of problems, as the individual workstation is now isolated from an async messaging and
scheduled job standpoint and is able to produce and consume messages locally without fear of receiving or interacting with
other message producers in the cluster. However, this configuration has the following drawbacks:
- There are a few soft references between entities in the Jobs/Events module and entities in the Enterprise module. In the shared database, these references are broken (the Jobs/Events side only exists on the developer workstation). This broken relationship can lead to problems with some of the resiliency functions present in the system - specifically the auto-retry function that is important for re-trying promotions and deployments that failed as the result of the promotion process being killed. A failure in this resiliency function can result in promotions and deployments that appear to be stuck in a in-progress state.
- Some events are important to be shared across the cluster, regardless of isolation level. Cache invalidation events are a good example of this. Other nodes should be notified of entity changes resulting from a deployment (even if that deployment was performed on a developer workstation) so each node's cache can be updated. This tries to make sure every node represents the current state of the shared database in a near real time fashion. With an isolated jobs and events persistence unit, the ability to share these types of events is lost.
To address some of these issues, Broadleaf has introduced the "Incognito" mode for the Jobs/Events module. This mode is
controlled via standard Spring properties, or system properties, and allows a developer workstation to launch against
a shared development database in a more isolated way, but without forcing the developer to maintain a local Jobs/Events
database. This mode also addresses some of the resiliency and cache invalidation issues noted previously.
Overall Environment Architecture
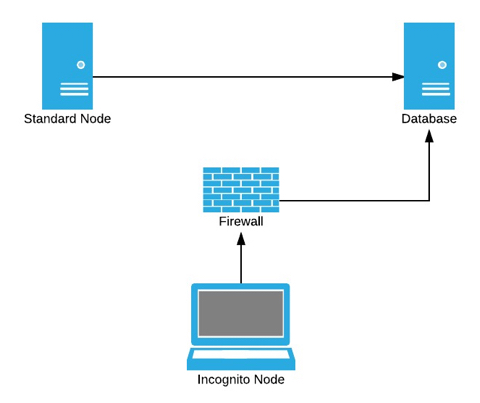
The architecture to facilitate this feature is relatively simple. The database acts as the cluster integration layer
(FYI, separate physical databases or schemas can be used for each of the Broadleaf persistence units, including the Jobs/Events
persistence unit). At least one standard node should be present in the cluster to handle master node functions and cluster
maintenance. Then any number of developer workstations can join the cluster as incognito members by running against the
same database (see prerequisites and configuration requirements below).
Prerequisites and Configuration
The following are required items to get a incognito enabled cluster running
- A incongito mode enabled database schema
- This is a standard Broadleaf Commerce installation schema, with several empty columns added
- A new empty, nullable varchar column is required entitled
INCOGNITO_IDon the tables:BLC_SCHED_JOB,BLC_REGISTERED_NODE, andBLC_SYSTEM_EVENT. - A new index on the
INCOGNITO_IDcolumn for each of the three tables.
- At least one standard node cluster member
- This is usually a site or admin instance of Broadleaf (either will do)
- No additional configuration for a standard cluster member is required
- A developer workstation started in incognito mode
- Set the
master.node.incognitoproperty to true (either in a property file, or passed as a system property) - Set the
master.node.incognito.idproperty to a reasonable id. This id is a string and should be unique enough that no one else will use it and descriptive enough to identify the individual developer as the owner. Set either in a property file, or pass as a system property.
- Set the
That's it! To help with obvious node type identification during startup, shortly after launch, a standard node will emit
the following to the console:
_____ __ __ __
/ ___// /_____ _____ ____/ ____ __________/ /
\__ \/ __/ __ `/ __ \/ __ / __ `/ ___/ __ /
___/ / /_/ /_/ / / / / /_/ / /_/ / / / /_/ /
/____/\__/\__,_/_/ /_/\__,_/\__,_/_/ \__,_/
--------------- Standard Mode -----------------
Incognito Environment - Standard Cluster Node
-----------------------------------------------
And shortly after launch, an incognito node will emit the following to the console:
____ _ __
/ _____ _________ ____ _____ (_/ /_____
/ // __ \/ ___/ __ \/ __ `/ __ \/ / __/ __ \
_/ // / / / /__/ /_/ / /_/ / / / / / /_/ /_/ /
/___/_/ /_/\___/\____/\__, /_/ /_/_/\__/\____/
/____/
-------------- Incognito Mode -----------------
Incognito Environment - Incognito Cluster Node
${info}
-----------------------------------------------
Characteristics and Restrictions
- Once the incognito environment is enabled (i.e. the
INCOGNITO_IDcolumns are added), cluster members will not be allowed to start withhibernate.hbm2ddl.autoset tocreateorcreate-drop. This tries to prevent accidental wiping of the shared database by a connecting incognito node. You should not depend on this feature alone for the safety of your data. See the best practices section below. - Scheduled jobs marked with an incognito id will only execute on an incognito node with that id
- SystemEvent instances created on an incognito node will only be visible to that node
- Admin Deployments and Promotions emitted from an incognito node will execute on that node. The exception to this is if the incognito node is killed during the coarse of the promotion. In such a case, the promotion or deployment is available for auto-retry by a standard cluster member only. This supports some notion of resiliency with the data state.
- Incognito nodes do not perform auto retries
- Cache invalidation (and several solr related SystemEvents) are exceptional in that they do not adhere to the normal isolation bounds. These events are shared by all members of the cluster (standard or incognito).
Best Practices
- With incognito mode, it is still possible for an incognito node to lock rows during a long running transaction (e.g. during debugging). Therefore, it is important for teams to be aware of each other and be good citizens of the cluster.
- A plan should be in place for periodic cleansing of the data. During the normal development lifecycle, it is likely that cruft data will build up as developers experiment and build functionality. Having a plan in place to remove cruft (either immediately, or periodically) is important.
- Consider using a "dev" user configured for login from the application to the shared database. This user should have
reduced priveleges (no table create or drop, etc...). Even with the restriction against
hibernate.hbm2ddl.autoin the cluster, it's good to add this additional layer of safety. - Don't use this mode in production. Access to production should be more strict. This mode has the possibility to impact performance and accidentally impact data.